AI nie widzi modelu BIM. AI widzi dane.
Dlaczego rozkład danych jest jednym z pierwszych pojęć w ML4BIM — od masy prawdopodobieństwa po całkowanie, na przykładach z instalacji MEP.
Dlaczego rozkład danych jest jednym z pierwszych pojęć, które warto zrozumieć w AI/ML
BIM często kojarzy się z geometrią.
Widzimy model 3D budynku, instalacje, kanały wentylacyjne, rury, urządzenia, pomieszczenia, ściany, stropy i przestrzenne zależności między elementami. Dla projektanta, koordynatora BIM albo inżyniera MEP model jest przede wszystkim cyfrową reprezentacją budynku.
Ale dla sztucznej inteligencji model BIM wygląda inaczej.
Dla AI model BIM to nie jest „budynek”.
To dane.
- średnice rur,
- długości kanałów,
- powierzchnie pomieszczeń,
- przepływy powietrza,
- grubości ścian,
- typy systemów,
- liczba kolizji,
- nazwy rodzin,
- parametry IFC,
- klasy elementów.
Sztuczna inteligencja nie patrzy na model tak jak człowiek. Nie widzi instalacji jako logicznego układu, dopóki nie przekształcimy ich w strukturę danych, z której może się uczyć.
I właśnie dlatego, zanim zaczniemy mówić o trenowaniu modeli AI dla BIM, warto zrozumieć podstawowe pytanie:
Jak rozkładają się nasze dane?
BIM jako zbiór danych
Wyobraźmy sobie prosty model instalacji wentylacyjnej.
Dla człowieka to układ kanałów, nawiewników, wywiewników, central wentylacyjnych, przepustnic i tłumików. Możemy go ocenić wizualnie, sprawdzić trasy, kolizje i zgodność z projektem.
Dla algorytmu uczenia maszynowego ten sam model może być tabelą:
| Element | Długość | Przekrój | System | Przepływ | Poziom |
|---|---|---|---|---|---|
| Kanał 1 | 1.2 m | 400 × 200 | Nawiew | 350 m³/h | +3.20 |
| Kanał 2 | 2.4 m | 500 × 250 | Nawiew | 620 m³/h | +3.20 |
| Kanał 3 | 0.8 m | 315 mm | Wywiew | 180 m³/h | +3.20 |
| Kanał 4 | 8.6 m | 800 × 400 | Nawiew | 2200 m³/h | +3.20 |
I dopiero na takim poziomie AI może zacząć „widzieć” wzorce.
Może zauważyć, że większość kanałów jest krótka.
Może wykryć nietypowo duże przepływy.
Może znaleźć elementy z brakującymi parametrami.
Może rozpoznać, że pewne typy elementów często występują razem.
Może pomóc przewidywać błędy, klasyfikować elementy albo optymalizować projekt.
Ale żeby to było możliwe, musimy najpierw rozumieć język danych.
Jednym z najważniejszych pojęć w tym języku jest rozkład danych.
Czym jest rozkład danych?
Rozkład danych opisuje, jakie wartości występują w zbiorze i jak często się pojawiają.
Przykład:
Załóżmy, że analizujemy długości kanałów wentylacyjnych w modelu BIM.
Mamy wartości:
0.6 m
0.9 m
1.1 m
1.4 m
1.8 m
2.2 m
2.6 m
8.5 m
12.0 mNa pierwszy rzut oka widać, że większość kanałów jest raczej krótka, ale pojawiają się też pojedyncze długie odcinki.
To już jest informacja o rozkładzie.
Nie interesuje nas tylko jedna średnia wartość. Interesuje nas kształt danych:
- gdzie wartości się skupiają,
- jak bardzo są rozproszone,
- czy występują wartości odstające,
- czy mamy dużo małych wartości i kilka bardzo dużych,
- czy dane są równomierne, czy mocno nierówne.
To są pytania, które mają ogromne znaczenie w uczeniu maszynowym.
Dlaczego średnia nie wystarczy?
W pracy inżynierskiej często lubimy jedną konkretną liczbę.
Średnia długość kanału.
Średnia powierzchnia pomieszczenia.
Średni przepływ powietrza.
Średnia liczba kolizji na kondygnację.
Problem polega na tym, że średnia może ukrywać prawdziwy obraz danych.
Weźmy taki przykład:
1.0 m, 1.2 m, 1.4 m, 1.6 m, 12.0 mŚrednia wynosi:
3.44 mAle czy typowy kanał w tym zestawie ma około 3.4 m?
Nie.
Większość kanałów ma długość około 1–2 m. Jeden długi odcinek mocno zawyżył średnią.
Dlatego w analizie danych oprócz średniej warto patrzeć też na medianę, zakres, kwartyle, odchylenie standardowe i wartości odstające.
W kontekście BIM to szczególnie ważne, bo modele często zawierają przypadki nietypowe:
- bardzo długie magistrale,
- bardzo duże lokale,
- pojedyncze elementy o błędnych jednostkach,
- źle opisane rodziny,
- elementy skopiowane z niepoprawnymi parametrami,
- braki danych w IFC.
Dla człowieka to czasem „jeden dziwny element”.
Dla modelu AI taki element może mocno zaburzyć proces uczenia.
Masa prawdopodobieństwa - gdy dane są dyskretne
Nie wszystkie dane w BIM są ciągłe.
Czasami analizujemy wartości, które są policzalne i występują jako konkretne przypadki.
Przykłady:
- liczba kolizji na kondygnacji,
- liczba urządzeń w pomieszczeniu,
- liczba nawiewników w strefie,
- liczba błędów walidacji IFC,
- klasa elementu: ściana, strop, dach, drzwi,
- typ systemu: nawiew, wywiew, zasilanie, powrót.
Takie dane nazywamy dyskretnymi.
Dla danych dyskretnych możemy mówić o prawdopodobieństwie konkretnej wartości.
Na przykład:
P(X = 2)czyli:
Jakie jest prawdopodobieństwo, że na danej kondygnacji wystąpią dokładnie 2 kolizje?To podejście nazywamy masą prawdopodobieństwa.
Masa prawdopodobieństwa przypisuje prawdopodobieństwo do konkretnych wartości.
Przykład:
| Liczba kolizji | Prawdopodobieństwo |
|---|---|
| 0 | 10% |
| 1 | 25% |
| 2 | 35% |
| 3 | 20% |
| 4 | 10% |
W tym przypadku możemy powiedzieć:
P(X = 2) = 35%Czyli istnieje 35% prawdopodobieństwa, że dana kondygnacja będzie miała dokładnie dwie kolizje.
To jest intuicyjne, bo liczba kolizji może wynosić 0, 1, 2, 3 i tak dalej. Są to konkretne, oddzielne wartości.
Gęstość prawdopodobieństwa - gdy dane są ciągłe
Inaczej wygląda sytuacja z danymi ciągłymi.
Dane ciągłe mogą przyjmować dowolną wartość w pewnym zakresie.
Przykłady z BIM i MEP:
- długość kanału,
- średnica rury,
- powierzchnia pomieszczenia,
- przepływ powietrza,
- temperatura,
- prędkość powietrza,
- strata ciśnienia,
- grubość przegrody.
Tutaj pytanie o dokładną wartość często traci sens.
Na przykład:
Jakie jest prawdopodobieństwo, że kanał ma dokładnie 1.473829 m?W praktyce takie pytanie nie jest użyteczne.
Długość kanału może mieć nieskończenie wiele możliwych wartości:
1.4 m
1.47 m
1.473 m
1.4738 m
1.47382 m
...Dlatego dla danych ciągłych nie pytamy zwykle o dokładną wartość.
Pytamy o przedział.
Na przykład:
Jakie jest prawdopodobieństwo, że długość kanału mieści się między 1 m a 2 m?Tutaj pojawia się pojęcie gęstości prawdopodobieństwa.
Gęstość prawdopodobieństwa mówi, gdzie wartości są bardziej skoncentrowane. Jeżeli krzywa gęstości jest wysoka w pewnym miejscu, oznacza to, że w tym obszarze pojawia się dużo wartości.
Ale sama wysokość krzywej nie jest jeszcze prawdopodobieństwem.
Prawdopodobieństwem jest dopiero pole pod krzywą dla danego zakresu.
Całkowanie bez straszenia matematyką
W tym miejscu pojawia się całkowanie.
Dla wielu osób brzmi to jak powrót do trudnej matematyki ze studiów. Ale intuicja jest dużo prostsza.
Całkowanie w tym kontekście oznacza liczenie pola pod krzywą.
Jeżeli mamy krzywą gęstości prawdopodobieństwa dla długości kanałów, to prawdopodobieństwo, że kanał ma długość od 1 m do 2 m, odpowiada polu pod krzywą właśnie między 1 a 2.
Można to sobie wyobrazić tak:
- Mamy krzywą opisującą rozkład długości kanałów.
- Wybieramy zakres, np. od 1 m do 2 m.
- Podświetlamy obszar pod krzywą w tym zakresie.
- Pole tego obszaru to prawdopodobieństwo.
Innymi słowy:
Prawdopodobieństwo = pole pod krzywąA całkowanie jest matematycznym sposobem obliczenia tego pola.
To bardzo ważna intuicja, bo wiele pojęć w uczeniu maszynowym i statystyce opiera się właśnie na tej relacji.
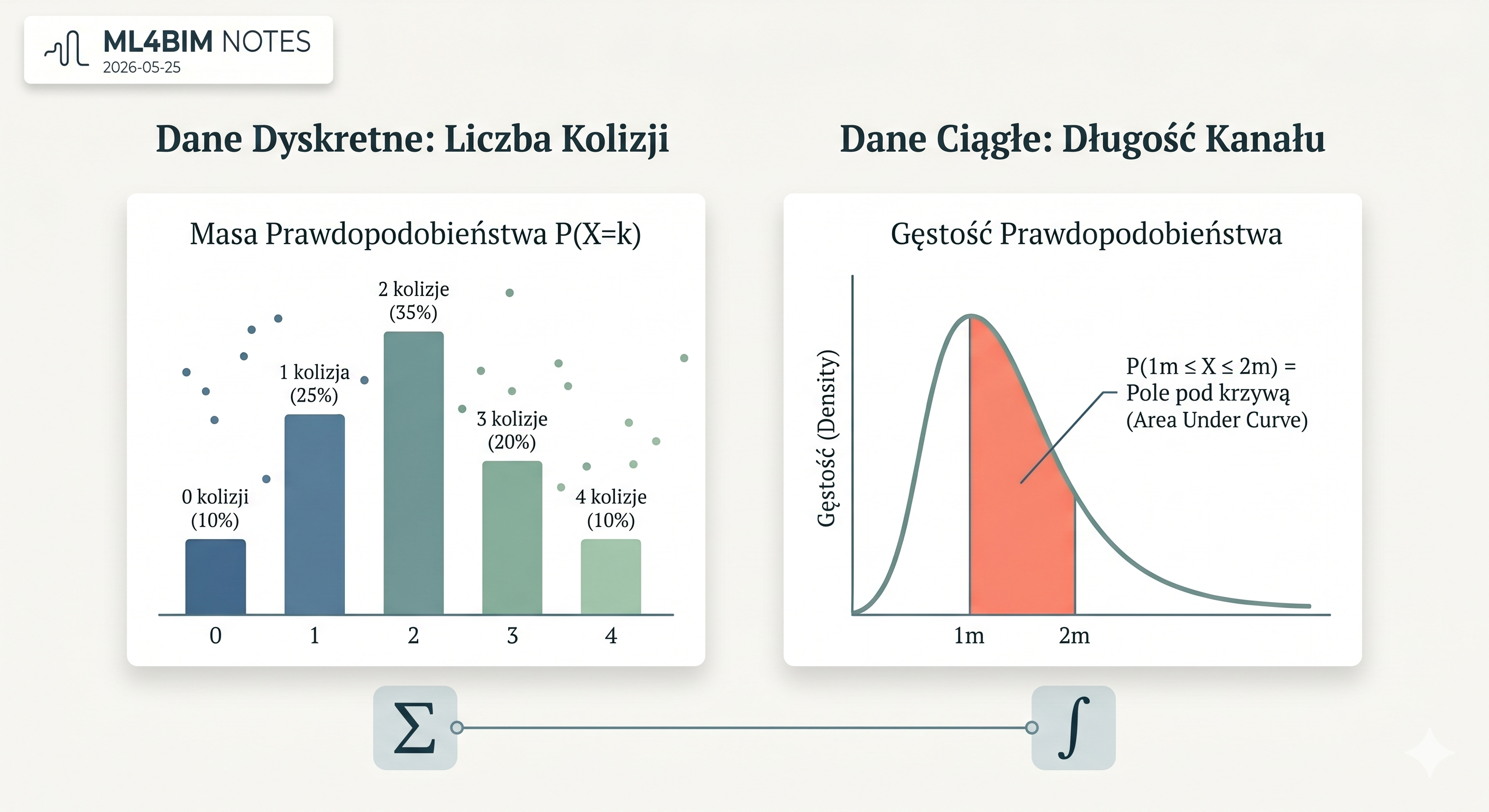
Suma czy całka?
Najprościej zapamiętać to tak:
Dla danych dyskretnych prawdopodobieństwa sumujemy.
Przykład:
P(X = 1) + P(X = 2) + P(X = 3)Dla danych ciągłych liczymy pole pod krzywą, czyli używamy całkowania.
Przykład:
P(1 ≤ X ≤ 2)Czyli:
prawdopodobieństwo, że wartość znajdzie się w zakresie od 1 do 2W wersji intuicyjnej:
sumowanie = dodawanie oddzielnych słupków
całkowanie = dodawanie bardzo wielu cienkich plasterków pod krzywąTo jest dokładnie ten moment, w którym matematyka zaczyna mieć praktyczny sens dla inżyniera.
Nie chodzi o wzory same dla siebie.
Chodzi o zrozumienie, jak model AI/ML interpretuje dane i ich rozkład — na wykresie powyżej widać oba podejścia obok siebie.
Przykład: długości kanałów wentylacyjnych
Załóżmy, że chcemy nauczyć model AI rozpoznawać nietypowe elementy w instalacji wentylacyjnej.
Jedną z cech wejściowych może być długość kanału.
Po analizie danych okazuje się, że:
- większość kanałów ma długość od 0.5 m do 3 m,
- część kanałów ma długość od 3 m do 6 m,
- pojedyncze kanały mają długość powyżej 10 m.
To mówi nam coś ważnego.
Kanał o długości 2 m jest typowy.
Kanał o długości 5 m jest mniej typowy, ale nadal możliwy.
Kanał o długości 30 m może być przypadkiem specjalnym albo błędem modelu.
Jeżeli taki rozkład pokażemy na histogramie, zobaczymy prawdopodobnie dużo wartości po lewej stronie i długi ogon po prawej.
To oznacza, że dane są skośne.
Dla AI ma to znaczenie, ponieważ model może bardzo dobrze nauczyć się typowych przypadków, ale gorzej radzić sobie z rzadkimi, nietypowymi elementami.
Rozkład danych a jakość modelu AI
W uczeniu maszynowym bardzo łatwo zachwycić się samym modelem.
Sieć neuronowa.
Regresja.
Klasyfikator.
Model językowy.
Agent AI.
Ale jakość modelu bardzo często zależy od czegoś mniej efektownego:
Od jakości i rozkładu danych wejściowych.
Jeżeli dane są źle opisane, model będzie uczył się błędnych wzorców.
Jeżeli jedna klasa dominuje, model może ignorować rzadkie przypadki.
Jeżeli wartości odstające nie zostaną sprawdzone, mogą zaburzyć predykcje.
Jeżeli jednostki są niespójne, model może nauczyć się chaosu.
Jeżeli dane treningowe pochodzą tylko z jednego typu projektu, model może nie działać dobrze na innych budynkach.
W AEC to szczególnie ważne, bo dane projektowe są często bardzo nierówne.
Jeden model może mieć dobrze uzupełnione parametry.
Drugi może mieć braki.
Trzeci może mieć inne nazewnictwo.
Czwarty może mieć niepoprawny eksport IFC.
AI nie rozwiązuje automatycznie tych problemów. AI je dziedziczy.
Dlatego analiza danych jest pierwszym krokiem do sensownego modelu ML.
Co powinien sprawdzić inżynier przed trenowaniem modelu?
Przed trenowaniem modelu AI/ML na danych BIM warto zadać kilka prostych pytań:
Jakie wartości występują najczęściej?
Czy są wartości odstające?
Czy dane są ciągłe czy dyskretne?
Czy klasy są zbalansowane?
Czy występują braki danych?
Czy jednostki są spójne?
Czy rozkład danych odpowiada rzeczywistości projektowej?
Czy dane pochodzą z wystarczająco różnych projektów?To nie są pytania akademickie.
To są pytania praktyczne.
Jeżeli chcemy klasyfikować przegrody, musimy wiedzieć, jakie typy przegród dominują w danych.
Jeżeli chcemy analizować instalacje HVAC, musimy wiedzieć, jak rozkładają się przepływy, średnice, długości i typy systemów.
Jeżeli chcemy wykrywać błędy w modelu IFC, musimy wiedzieć, jak wygląda „normalny” model, zanim zaczniemy wykrywać anomalie.
Najważniejsza intuicja
BIM jest geometrią dla człowieka.
Ale dla sztucznej inteligencji BIM jest zbiorem danych.
A dane mają rozkład.
Rozkład mówi nam, co jest typowe, co jest rzadkie, co jest podejrzane i czego model AI może się nauczyć.
Dla danych dyskretnych pracujemy z masą prawdopodobieństwa.
Dla danych ciągłych pracujemy z gęstością prawdopodobieństwa.
Dla danych dyskretnych prawdopodobieństwa sumujemy.
Dla danych ciągłych liczymy pole pod krzywą, czyli używamy całkowania.
I chociaż brzmi to matematycznie, praktyczna intuicja jest bardzo prosta:
AI nie uczy się z magii. AI uczy się z rozkładu danych.
Podsumowanie
Jeżeli chcemy rozwijać sztuczną inteligencję dla BIM, nie możemy zaczynać wyłącznie od modeli AI.
Musimy zacząć od danych.
Od ich jakości.
Od ich struktury.
Od ich rozkładu.
Od ich ograniczeń.
Dopiero wtedy modele uczenia maszynowego mogą mieć sens.
W projektach BIM i MEP dane są często chaotyczne, niespójne i zależne od standardów konkretnego biura, projektu lub eksportu IFC. To nie jest przeszkoda nie do pokonania. To po prostu rzeczywistość, którą trzeba zrozumieć i uporządkować.
Dlatego data literacy, czyli umiejętność czytania i rozumienia danych, będzie jedną z kluczowych kompetencji przyszłego inżyniera BIM.
Bo zanim BIM stanie się naprawdę inteligentny, musi stać się mierzalny.
ML4BIM Note #01
W tym artykule pokazuję, dlaczego pojęcie rozkładu danych jest kluczowe dla wykorzystania AI w BIM. Na przykładach z instalacji MEP wyjaśniam różnicę między masą prawdopodobieństwa, gęstością prawdopodobieństwa i całkowaniem - bez akademickiego żargonu, z perspektywy praktycznego inżyniera.